Linux内存管理
内存是计算机的首要存储,为进程提供数据保存的位置
阅读Vamei的文章受益匪浅,谨以此文悼念
内存简述
内存,顾名思义,是计算机的内部存储,是主存储。操作系统内核以及应用程序运行时产生的数据都存储在内存当中。
内存可以看做是一片数据存储空间。内存有一个最小的存储单位,通常为一字节。内存会为其每一个存储单位进行编号,该编号称为内存地址。内存地址从0开始,每一个单位加1,这样的方式称为线性地址。内存地址通常使用十六进制来表示,我们经常可以在各类异常信息中看到0x1A000E27这种字样,其中0x表示十六进制,后面便是内存地址。
内存地址存在上限,其范围和CPU地址总线的位宽相关。 其实很容易理解,CPU要获取内存上的数据,就要请求一个地址,而CPU能表达的地址上限,就是内存地址的上限。以32位CPU为例,其总线宽度为32,每一位能通过高低电压表示1或0,因此可以表示一个32位的二进制数,将该范围的二进制转换为十六进制便是0x00000000-0xFFFFFFFF。这就代表32位的CPU支持的内存上限大概是4GB左右。
内存的存储采用了随机读取存储(RAM,Random Access Memory)。 随机的意义是获取内存所需要的时间与内存的存储位置无关。即我们获取一个地址很靠后的内存单元数据,等待的时间并不会比获取第一个地址的内存单元数据长,做到以公平的时间获取内存数据。
Linux内存管理
现代操作系统的内存管理机制有两种:段式管理和页式管理。
段式内存管理,就是将内存分成段,每个段的起始地址就是段基地址。地址映射的时候,由逻辑地址加上段基地址而得到物理地址。
页式内存管理,内存分成固定长度的一个个页片。地址映射的时候,需要先建立页表,页表中的每一项都记录了这个页的基地址。
严格说Linux采用段页式内存管理,也就是既分段,又分页。地址映射的时候,先确定对应的段,确定段基地址;段内分页,再找到对应的页表项,确定页基地址;再由逻辑地址低位确定的页偏移量,就能找到最终的物理地址。
但是,实际上Linux采用的是页式内存管理。原因是Linux中的段基地址都是0,相当于所有的段都是相同的。这样做的原因是某些体系结构的硬件限制,比如Intel的i386。作为软件的操作系统,必须要符合硬件体系。虽然所有段基地址都是0,但是段的概念在Linux内核中是确实存在的。比如常见的内核代码段、内核数据段、用户态代码段、用户态数据段等。除了符合硬件要求外,段也是有实际意义的。
虚拟内存
我们都知道,程序运行时的数据都是存储在内存当中,但实际上进程并不能直接访问物理内存。在Linux下,进程并不能读取或写入某个物理地址的内存,其能访问的只能是虚拟地址。而操作系统会将虚拟内存地址翻译为真实物理内存地址,这用内存管理方法称为虚拟内存。
每一个进程都有一套自己的虚拟内存地址,各个进程之间的虚拟内存地址是相互独立的,即不同的进程可能用了相同的某个内存地址来存储自己的数据。如下图所示,进程1、2都在操作自己空间内的0x10001000的地址,但实际上操作系统会将其翻译为不同的物理内存地址。
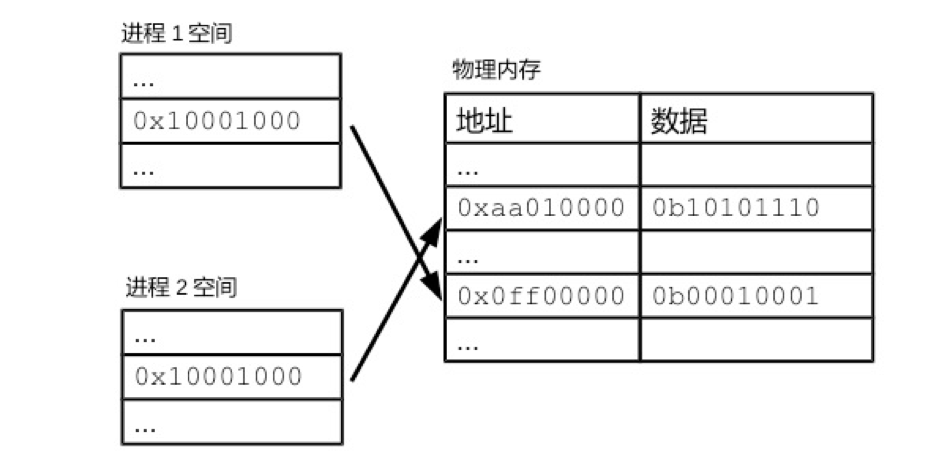
物理内存地址对于进程来说是不可见的,进程中出现的所有内存地址都是虚拟内存地址,因此通过程序所表达出的内存地址都是虚拟内存地址。通过这种屏蔽,剥夺了应用程序随意访问物理内存的权限,所有的内存操作都由操作系统来把关。
程序之间也通过虚拟内存实现了内存空间的互相独立,减少出错的可能性。同时程序间共享内存也变得简单,操作系统只需要将同一块物理内存映射到需要共享内存的进程空间即可。内核和共享库的映射,就是通过这种方式实现的。每个进程空间中,最初一部分的虚拟内存地址都会对应到物理内存中预留给内核的空间,这样所有的进程便能共享一个内核。
内存分页
虚拟内存在带来便利性和安全性的同时,也会在转换的过程中消耗计算机的资源。
为了尽量降低资源消耗,就需要简化转换过程,而将所有的对应关系都记录在一张表上是最简单的方法。但如果为每一个字节的内存都记录其转换关系,那么记录关系的表也是非常庞大呢,光是表都会占据很大的内存空间。因此Linux采用了分页的方式来记录内存对应关系。
所谓内存分页就是以页为单位来管理一片内存,即重新规划我们管理的内存最小单位。通常每个页的大小为4KB,即一页有4096个字节的内存。Linux会把物理内存和虚拟内存都分割成页。内存分页之后,系统便只需要记录页之间的对应关系,这样需要记录的数量就能大大减少。
无论是虚拟内存页还是物理内存页,一页内的地址都是连续的,这样的话页之间对应起来,页内的内存地址也可以一一对应。这也意味着虚拟内存页和物理内存页地址有一段尾数是相同的:按一页有4096字节来算,4096是2的12次方,即地址的后12位(二进制)对于两个页来说是完全对应的。我们把这段完全一致的地址称为偏移量,偏移量实际上表达的是地址在一页中的位置。而除去偏移量的前一部分是页编号,操作系统只需要记录页编号的对应关系就可以了。
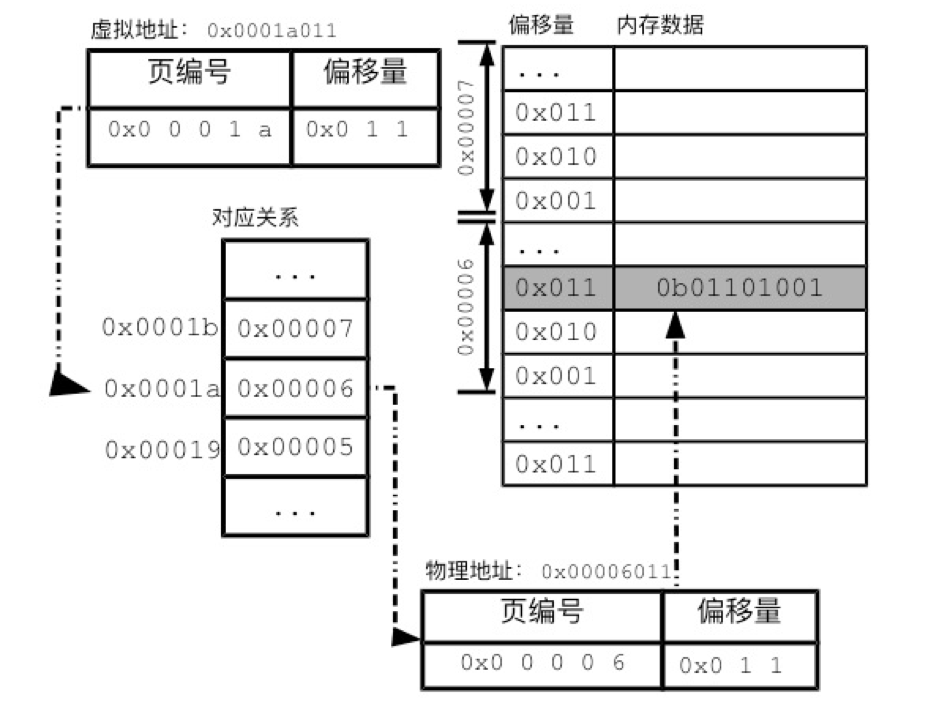
多级分页表
为了保证Linux内存管理的灵活性,每一个进程都会有一个分页表,且为了保证查询速度,分页表也会被存储在内存中。
我们可以想象最简单的分页表就是一个线性对应表,记录所有的页对应关系。但这样的记录方式存在明显的弊端:比如我们知道程序在运行时会为可增长的数据结构预留空间,如果采用这种线性记录方式,很可能有很多页表记录仅仅是被预留但并没有使用,效率是比较低的。要提高利用率,就需要细化我们记录的内容,因此Linux采用了多层分页表,减少记录表所需要的空间。
我们通过一个简单的例子来了解Linux的多级分页表。之前我们提到地址被分为了页编号和偏移量两部分,对于多级分页表来说,会进一步分割页编号。用两层甚至多层的方式来记录页编号的对应关系。如下图所示
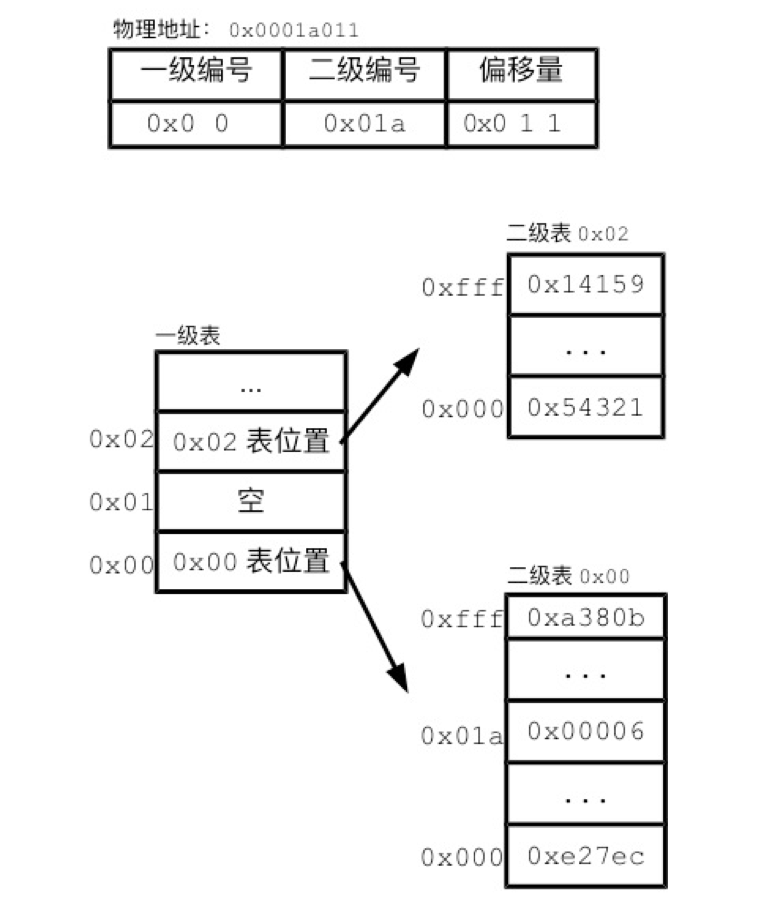
在该例中,页编号被分为了两级,第一级是两位十六进制,对应了8位页编号,第二级是三位十六进制,即12位页编号。一级表对应了一级编号到二级编号的映射,而二级表便对应了二级编号到物理页的映射。因此,每一个二级表所对应的页编号的8位前缀也是一样的。
这种对应方式类似于电话号码的区号,如果有某个前缀并没有被使用,那么其对应的下一级记录标记为空就可以了,节省了许多记录的空间。除此之外,这种方式也便于记录不连续、分散在不同位置的内存,这样操作系统也更方便去利用零碎内存空间。
对64位的CPU来说,Linux采用了通用的四级页表。对于32位x86系统,两级页表已经足够了。
- 页全局目录(page global directory):多级页表的抽象最高层
- 页上级目录(page upper directory):即pud
- 页中间目录( page middle directory):即pmd 页表的中间层
- 页表(page table entry):pte
Linux通过使“页上级目录”位和“页中间目录”位全为0,彻底取消了页上级目录和页中间目录字段。不过,页上级目录和页中间目录在指针序列中的位置被保留,以便同样的代码在32位系统和64位系统下都能使用。