分布式异步工作流 -- Temporal 介绍与使用
为什么我们需要这样的工作流组件
在实际生产中存在很多这样的业务场景:一个完整业务流程由许多单体业务步骤组成,每个单体业务可以分布式的异步完成,但某些业务步骤之间又存在一定的顺序依赖关系。
这样的场景下,整个业务便呈现一种流式的排布。如果没有顺序依赖的话,使用简单的多生产者多消费者模型即可满足我们的需求,但当需要对顺序进行控制或依赖前一个过程的结果时,工作流便成了一个非常方便的解决方案。
举例来说,设想一个视频站点的业务。用户上传视频后,我们需要将视频送去给图像组做水印检测、送去给推荐组做视频分类,之后我们需要对图像组修改过的视频进行格式调整,再进行多种编码格式、码率、分辨率的视频调整,最终将每个步骤产生的视频汇总,更新这个视频在数据库中存储的相关资源链接。在这个过程中转码操作依赖于图像组给回的视频源,最终视频更新资源要使用各个阶段输出的资源链接,这是明显的顺序和结果依赖;而多种编码、码率、分辨率的调整完全可以并发的异步进行,可以视为是无状态的任务。这种情景下既要保证依赖可靠,又要提升性能和处理速度,分布式的异步工作流便成为了首选。
先说结论
我们的业务场景是基于 Golang 的,在经过对比后我们选择的是本文的标题中所提到的 Temporal。
Temporal 前身是 Uber 的内部工作流组件 Cadence,是一个封装的比较好的工作流编排引擎。由 Go 编写,客户端支持 Go 和 JAVA(其他客户端也在积极开发中),通过 Docker 和 K8S 部署可以达到开箱即用的效果。
有相关需求或感兴趣的同学可以继续向下阅读
对比与选型,优势在哪里?
可编排异步任务队列 Vs Temporal
对于异步任务这样的场景我们首先会想到的是异步任务队列,即多生产者多消费者的模型,这是一种非常常见的解决方案,那么如果我们在异步任务队列上增加对工作流编排的支持呢?
抱着这种想法我们找到了基于 Golang 的异步任务工作流框架 Machinery,其在 Github 上也非常受欢迎,有近 4500 的 stars。接着我们将其与 Temporal 做了对比,详细如下
部署拓扑
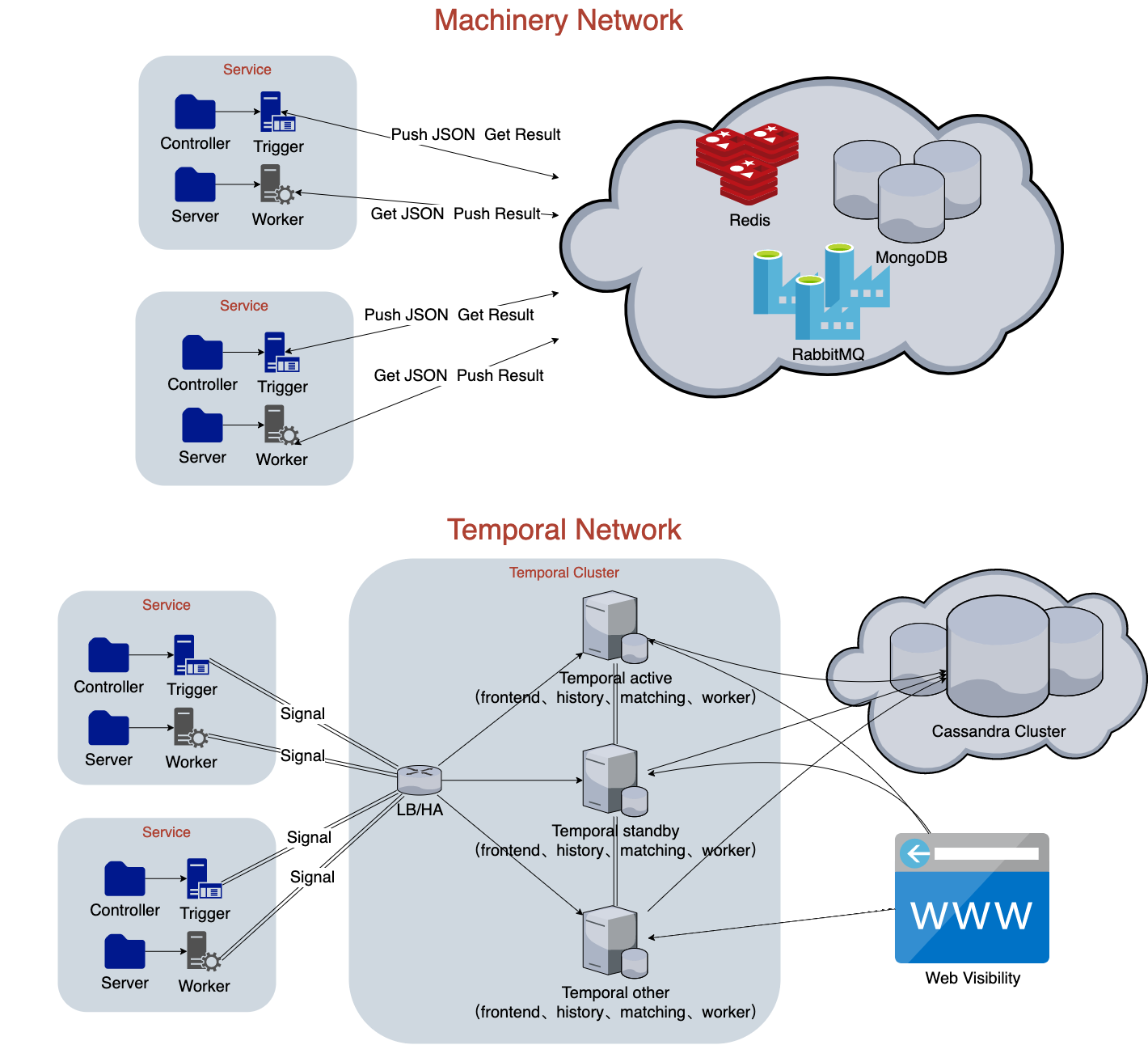
两者部署后的网络拓扑如上图
Machinery 本质上依赖于单个中间件做队列,Worker 做全异步的消费,即多生产者多消费者模型。
Temporal(Cadence)是一个引擎,本身可视为一个中间件,其依赖外部的相关组件做持久化、通信等,由自身来实现工作流编排和调度,实现任务的收集与分发。Temporal 本质上有多个组件组成,但如果使用 Docker 的话,对客户端来说也是单点接入的,实际使用起来并不会增加复杂度。
代码架构
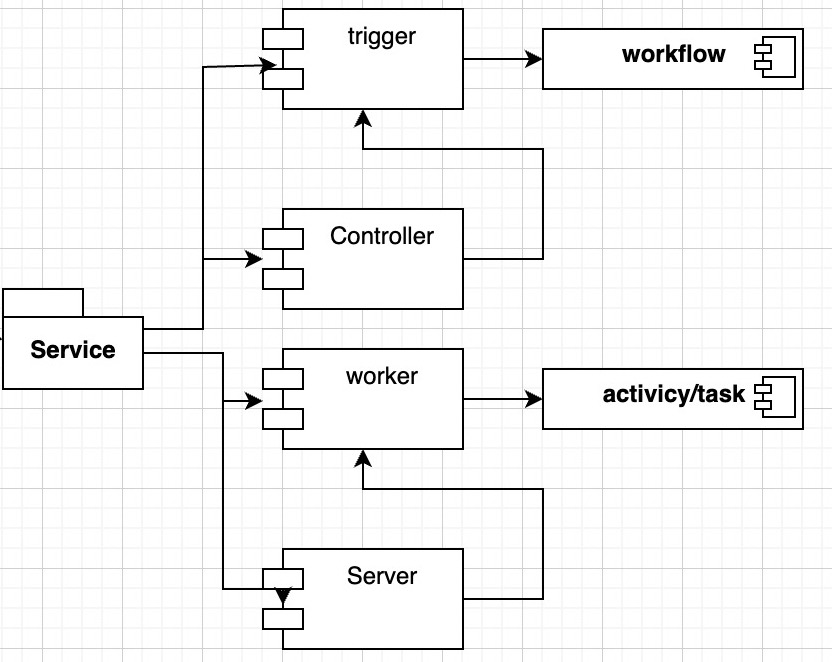
两者的代码结构类似,从微服务的角度来看,都是在 Gateway 层做触发,即生产者;在 Service 层做 Worker,即消费者
不同之处在于 Machinery 偏向于在生产侧做简单工作流编排,而 Temporal 偏向于在 Worker 消费侧做复杂工作流编排。两者的简单实例代码如下:
- Machinery
// Worker
// 任务具体逻辑
func Add(args ...int64) (int64, error) {
sum := int64(0)
for _, arg := range args {
sum += arg
}
return sum, nil
}
// 注册任务
tasks := map[string]interface{}{
"add": exampletasks.Add,
}
// Trigger
// 生成任务参数
var addTask0 = tasks.Signature{
Name: "add",
Args: []tasks.Arg{
{
Type: "int64",
Value: 1,
},
{
Type: "int64",
Value: 1,
},
},
}
// 发送任务请求
asyncResult, err := server.SendTaskWithContext(ctx, &addTask0)
if err != nil {
return fmt.Errorf("Could not send task: %s", err.Error())
}
// 获取任务结果
results, err := asyncResult.Get(time.Duration(time.Millisecond * 5))
if err != nil {
return fmt.Errorf("Getting task result failed with error: %s", err.Error())
}
log.INFO.Printf("1 + 1 = %v\n", tasks.HumanReadableResults(results))
- Temporal
// Worker
// 具体活动逻辑
func Activity(ctx context.Context, name string) (string, error) {
return "Hello " + name + "!", nil
}
// 编排workflow
func Workflow(ctx workflow.Context, name string) (string, error) {
ao := workflow.ActivityOptions{
ScheduleToStartTimeout: time.Minute,
StartToCloseTimeout: time.Minute,
}
ctx = workflow.WithActivityOptions(ctx, ao)
logger := workflow.GetLogger(ctx)
var result string
err := workflow.ExecuteActivity(ctx, Activity, name).Get(ctx, &result)
if err != nil {
logger.Error("Activity failed.", "Error", err)
return "", err
}
return result, nil
}
// 注册启动worker
w := worker.New(c, "hello-world", worker.Options{})
w.RegisterWorkflow(helloworld.Workflow)
w.RegisterActivity(helloworld.Activity)
err = w.Run(worker.InterruptCh())
if err != nil {
log.Fatalln("Unable to start worker", err)
}
// Trigger
// 调用workflow
workflowOptions := client.StartWorkflowOptions{
ID: "hello_world_workflowID",
TaskQueue: "hello-world",
}
we, err := c.ExecuteWorkflow(context.Background(), workflowOptions, helloworld.Workflow, "Temporal")
if err != nil {
log.Fatalln("Unable to execute workflow", err)
}
// 同步等待完成
var result string
err = we.Get(context.Background(), &result)
if err != nil {
log.Fatalln("Unable get workflow result", err)
}
log.Println("Workflow result:", result)
可以看到 Machinery 的任务编排需要手动撰写 JSON 格式参数,代码比较简单,虽然易读但也容易混乱。而对比 Temporal 的代码封装性较强,工作流编排都是基于封装好的调用,提升可靠性的代价便是维护上提高了成本。
对比总结
最后做一个对比总结
| Machinery | Temporal(Cadence) | |
|---|---|---|
| 介绍 | 开源异步队列任务框架,支持工作流编排,Github 4400 stars | Uber 开发的异步工作流引擎,Github 800+(4100) stars |
| 任务队列 | RabbitMQ、Redis、MongoDB等中间件 | 自身维护消息队列 |
| 持久层 | 无 | Cassandra、MySQL 等 |
| 历史浏览 | 无 | Web页面可视化、ES 搜索 |
| 架构部署 | 简单,本身是一个框架,无新引入组件 | 复杂,要新引入部署一个服务并引入服务发现,不使用 Docker 时二进制部署较困难 |
| 代码结构 | 简陋,使用 JSON 数据通信,代码中字符串定义会较多,较易读;多任务工作流编排倾向于在 Trigger 侧 | 优雅,使用信号传递通信,代码集成度高,不易读;多任务工作流编排倾向于在 Worker 侧 |
| 功能性 | 请求单位为一个 task,需要在 Trigger 侧手动处理各种结果和分支功能性简单 | 请求单位为一个 workflow,任务调度与结果处理在 Worker 侧的 workflow 中已经编排,功能性强 |
| 实现 | 多生产者多消费者框架,中间件作为队列,Trigger 编排并生产请求,Worker 异步消费请求 | Temporal 服务作为编排调度引擎,Worker 先编排工作流注册到服务,Trigger 直接对服务发送调度请求 |
实际上任何业务场景都应该根据自身的需要来选择合适的中间件,在某些场景下 Machinery 未尝不是一个好的选择。但对于我们的业务来说,各步骤依赖性较强、各分支结果多样化;存在外部事件;对失败重试、手动重放要求高;对历史记录及中间过程有可视性要求,显然简单的异步队列框架无法满足我们的需求。
Cadence Vs Temporal
在确定抛弃 Machinery 后,我们再来谈一谈 Cadence 和 Temporal。
实际上 Cadence 在 Github 上也已经拥有 4000+ 的 stars,已经是在业界有一定知名度的工作流引擎了。在探索 Cadence 的使用时,我发现了 Temporal
Temporal workflow vs Cadence workflow – Stack Overflow
简而言之,Temporal 是原 Cadence 联合创始人离开 Cadence 后基于其 Fork的新分支,从某种程度上来讲,Temporal 可能是 Cadence 的一个更商业化的版本,毕竟后者原先只是 Uber 内部的一个组件。也正如这个问答中有人提到的,Temporal 作为新公司产品开发后,可能会更多的拥抱业界普遍性的业务场景,相比较起来,它们也正处在高速的版本迭代中。
但 Temporal 和 Cadence 到底该使用哪一个呢?这恐怕需要大家自己来定夺,我简单罗列一下两者目前的区别:
- Temporal 的特点
- 将数据通信、存储由 Cadence 原来使用的 Thrift 更改为了Protocol Buffers,当然这可能对于使用者来说感觉不明显
- 组件间通信由原 Uber 的TCP 多路复用协议 TChannel 更改为了 gRPC,gRPC 的好处是客户端可以轻松使用其自带的 DNS 解析 实现负载均衡
- 组件间通信全面支持 TLS 加密,双向 TLS 加密对于安全性要求较高的场景更适用
- 优化了组件间配置及工作流数据流转
- 优化了客户端使用以及多语言的支持
- 高速的版本迭代(你很难说这是个优点还是个缺点,毕竟带来新 feature 的同时也可能带来新 bug)
- Cadence 的特点
- Cadence 的 Web 服务可以对多集群的数个 Server 同时连接,从而获取全部的历史。但 Temporal 当前只能连接一个 Server,这取决于通信方式采用 gRPC 的局限性,当然官方也表示该功能正在积极开发中
- Cadence 声称其已经完全移除了 Kafka 的依赖,而 Temporal 的多集群化仍需要 Kafka 的支持
- Cadence 正在推广自己的开源社区化,会有更多的人加入到 Cadence 开发中,目前来看其迭代速度并不亚于 Temporal
如果你去他们的 Github 逛一下,你会发现两者在 RoadMap 上已经有不同的侧重点了,至于选择使用哪一个,就由你们自己来决定吧。由于我们在生产上已经部署过 Cadence,作者在对比后打算尝一尝鲜,便选择了 Temporal,实际两者就目前来看区别还不算特别大。接下来的内容是与 Temporal 强相关,部分内容同样适用于 Cadence。
部署与实战细节
部署方案
使用 Docker 和 K8S
使用 Docker 就是为了更便捷的部署,因此直接按照官方推荐的步骤执行就可以开箱即用的部署好 Temporal 了
单 Docker 部署可以直接参考 这里
使用 K8S 部署可以参考 这里
使用二进制部署
虽然 Docker 使用起来非常便捷,但仍有许多业务场景的生产环境部署还不支持 Docker 化,作者就是这种情况,因此我花了很多时间研究了 Temporal 的二进制部署,保证实现一个多集群高可用的部署方案
Tips: Temporal 服务包含 frontend、matching、history、worker 几个内部组件,这些组件构成一个完整的 Temporal 二进制,官方也将其称为一个 Temporal 集群。而要构建高可用的 Temporal 服务,就需要使用多个二进制,部署多集群,官方称之为跨DC部署(Multi-DC)。
-
首先我们需要 clone 好 Temporal 的源码,在根目录下
go mod vendor装好依赖,执行make bins可以获得我们需要的相关二进制 -
准备依赖的组件,如果做测试用可以使用根目录下 docker/dependencies/ 目录下的 Docker 文件,这个 Docker 包含了使用 Temporal 的全部依赖。否则的话需要自己替换相关的组件地址, Cassandra 或 MySQL、Kafka 是必备的;如果需要支持搜索历史,要准备 ElasticSearch;如果要监控服务状态,要准备 Prometheus 或 Stat 和 Grafana;如果要支持工作流跟踪要准备 Jaeger
-
注册好存储,以 Cassandra 为例,可以直接执行
make install schema来调用 Makefile 来完成,记得替换地址和用户名密码。如果是部署集群则应执行install-schema-cdc -
注册要使用的命名空间,可以直接使用命令行工具:执行
./tctl n re --ns space_name,如果是集群部署,则应执行./tctl n re --ns space_name --gd true --cl active standby other -
调整配置文件,Temporal 依赖于配置文件的读取,在 config 目录下可以看到相关的配置,如果是集群部署,则按照角色名称读取
development_active.yaml``development_standby.yaml等,否则读取development.yaml。另有部分配置存放于dynamicconfig/development.yaml-
启动自动转发。在使用多集群时,非活跃集群不会处理发送到他那里的请求,因此需要将请求转发到活跃集群,可以配置开启自动转发,在
dynamicconfig/development.yaml中增加配置system.enableNamespaceNotActiveAutoForwarding: - value: true constraints: {} -
设置 BindOnIP。二进制部署服务到服务器上,并为局域网中的其他设备提供服务时,要设置为 BindOnIP 模式,在
development.yaml中设置 frontendbindOnIP: "0.0.0.0"(只有 frontend 需要对外服务) -
配置 Metrics 导出。以 Prometheus 为例,在
development.yaml中配置各节点的导出方式为 Prometheus,同时建议配置对应 Tag,以支持官方提供的 Grafana 模板。如果使用的是 K8S,可以直接使用官方提供的 Grafana 模板;如果使用的是二进制部署的多集群,可以参考我修改后的 Grafana 模板 -
如需要接入 ElasticSearch 实现查询,在
development.yaml中配置 ES -
在
development.yaml中配置存储、Kafka、各节点通信信息,完整配置如下persistence: defaultStore: cass-default visibilityStore: cass-visibility advancedVisibilityStore: es-visibility numHistoryShards: 4 datastores: cass-default: cassandra: hosts: "hostport" keyspace: "temporal_active" user: "cassandra" password: "password" cass-visibility: cassandra: hosts: "hostport" keyspace: "temporal_visibility_active" user: "cassandra" password: "password" es-visibility: elasticsearch: url: scheme: "http" host: "hostport" username: "elastic" password: "password" indices: visibility: temporal-visibility-dev global: membership: name: temporal_active maxJoinDuration: 30s broadcastAddress: "127.0.0.1" pprof: port: 7936 services: frontend: rpc: grpcPort: 7233 # grpcPort 用于组件间通信,frontend 也是提供给客户端连接的端口 membershipPort: 6933 bindOnLocalHost: false bindOnIP: "0.0.0.0" # frontend 设置为 bindOnIP metrics: prometheus: timerType: "histogram" listenAddress: "10.12.4.32:8000" # 设置导出 Metrics 的地址 tags: type: "frontend" # 设置 tag 方便使用 Grafana 模板 matching: rpc: grpcPort: 7235 membershipPort: 6935 bindOnLocalHost: true metrics: prometheus: timerType: "histogram" listenAddress: "10.12.4.32:8001" tags: type: "matching" history: rpc: grpcPort: 7234 membershipPort: 6934 bindOnLocalHost: true metrics: prometheus: timerType: "histogram" listenAddress: "10.12.4.32:8002" tags: type: "history" worker: rpc: grpcPort: 7940 membershipPort: 6940 bindOnLocalHost: true metrics: prometheus: timerType: "histogram" listenAddress: "10.12.4.32:8003" tags: type: "worker" clusterMetadata: # 配置多集群信息 enableGlobalNamespace: true replicationConsumer: type: kafka # 指定使用 Kafka 进行多集群通信 failoverVersionIncrement: 10 masterClusterName: "active" currentClusterName: "active" clusterInformation: active: enabled: true initialFailoverVersion: 1 rpcName: "frontend" rpcAddress: "10.12.4.32:7233" standby: enabled: true initialFailoverVersion: 2 rpcName: "frontend" rpcAddress: "10.12.4.33:7233" other: enabled: true initialFailoverVersion: 3 rpcName: "frontend" rpcAddress: "10.12.4.83:7233" dcRedirectionPolicy: # 请求转发配置 policy: "selected-apis-forwarding" toDC: "" kafka: tls: enabled: false certFile: "" keyFile: "" caFile: "" clusters: test: brokers: # Kafka 集群配置 - 10.12.3.252:9092 - 10.12.4.26:9092 - 10.12.4.27:9092 topics: active: cluster: test active-dlq: cluster: test standby: cluster: test standby-dlq: cluster: test other: cluster: test other-dlq: cluster: test temporal-visibility-dev: cluster: test temporal-visibility-dev-dlq: cluster: test temporal-cluster-topics: active: topic: active dlq-topic: active-dlq standby: topic: standby dlq-topic: standby-dlq other: topic: other dlq-topic: other-dlq applications: visibility: topic: temporal-visibility-dev dlq-topic: temporal-visibility-dev-dlq archival: history: state: "enabled" enableRead: true provider: filestore: fileMode: "0666" dirMode: "0766" visibility: state: "enabled" enableRead: true provider: filestore: fileMode: "0666" dirMode: "0766" namespaceDefaults: archival: history: state: "enabled" URI: "file:///tmp/temporal_archival/development" visibility: state: "enabled" URI: "file:///tmp/temporal_vis_archival/development" publicClient: hostPort: "10.12.4.32:7233" dynamicConfigClient: filepath: "config/dynamicconfig/development_es.yaml" pollInterval: "60s"
-
-
如果接入了 ElasticSearch,需要对 ElasticSearch 创建索引。直接使用
./schema/elasticsearch/visibility/index_template.json模板文件curl -X PUT http://ip:9200/_template/temporal-visibility-template -H 'Content-Type: application/json' --data-binary "@./schema/elasticsearch/visibility/index_template.json" curl -X PUT http://ip:9200/temporal-visibility-dev执行请求到 ES 来完成索引创建
至此我们的 Temporal 多集群已经部署完毕了,对每个集群的服务执行对应的命令完成启动即可。
如果仍有对部署不明确的步骤,可以直接查看 docker 目录下的 start.sh 脚本,是拉起 Docker 的预准备脚本,其本质便是依赖项的相关配置。
实战细节
除了部署外,我们在使用客户端时仍有许多细节要注意
-
活跃集群不会自动转移。当前如果活跃集群(即主机)挂掉,其他集群并不会自己选举出一个新的活跃集群,需要手动进行活跃集群转移。但放心,由于有持久化存储和非活跃集群的消息转发,请求和执行历史并不会丢失。
-
请求负载均衡。要保证高可用性,请求自然不能只发送到单一机器,否则主机挂掉请求就丢失了。如果是使用 K8S,其内部应该做了相关的负载均衡策略。但如果是多个单集群 Docker 部署或二进制多集群部署,需要我们自己处理负载均衡。
比较合适的方法是将 Temporal 服务集群 IP 实现 DNS 解析。无论通过哪种方式(作者使用的是 consul 做服务发现,将 Temporal 注册为服务后就可以使用consul 提供的 DNS 功能了)将 Temporal 的 IP 显示 DNS 解析后,客户端只需要配置 gRPC 支持的 DNS 格式即可完成请求的多 IP 轮询,样例如下
dns://dns_server_ip:dns_port/temporal_service_domain:temporal_port -
Worker 需要轮询所有的集群。当前一个 Worker 只能轮询一个集群获取任务,当活跃集群发生转移时,Worker 需要从新的活跃集群上获取任务,因此所有的集群都应该被 Worker 所监听轮询。作者的建议是创建 Worker 的代码直接构建一个 Worker 池,池内会有多个 Worker 实例监听所有的集群。样例如下:
func StartWorkerPool(t string) (err error) { hostMap := make(map[string]struct{}, 0) /* 该部分代码是使用了 Consul 提供的服务发现获取所有 Temporal 节点,可以自行根据自己的实现来完成该步骤 */ conf := consulApi.DefaultConfig() cClient, err := consulApi.NewClient(conf) //非默认情况下需要设置实际的参数 if err != nil { _ = logger.Error("get temporal server list failed, err %v", err) return } servicesData, _, _ := cClient.Health().Service("temporal", "", true, &consulApi.QueryOptions{}) for _, data := range servicesData { hostMap[data.Node.Address] = struct{}{} } /* END */ for host := range hostMap { err = newWorker(host, t) if err != nil { _ = logger.Error("create worker with host %v err %v", host, err) return err } } return nil } func newWorker(hp, t string) error { // The client and worker are heavyweight objects that should be created once per process. c, err := client.NewClient(client.Options{ HostPort: hp + ":7233", Namespace: nameSpace, Tracer: opentracing.GlobalTracer(), }) if err != nil { _ = logger.Error("new client err %v", err) return err } // 打开 Session 绑定功能 w := worker.New(c, common.TaskQueue, worker.Options{ EnableSessionWorker: true, }) regWorkflow(w, t) // 注册 Worker 监听的工作流,建议自行根据代码结构实现此函数 regActivities(w, t) // 注册 Worker 监听的活动,建议自行根据代码结构实现此函数 err = w.Start() if err != nil { _ = logger.Error("Unable to start worker, err %v", err) return err } return nil } -
客户端即 Worker 侧的工作流执行可以通过 Tracing 来跟踪,以 Golang 为例,Temporal 支持使用 OpenTracing,配合 Jaeger 可以实现工作流的耗时追踪。只需要在初始化 Worker 时同步初始化 OpenTracing 的 GlobalTracer,并在创建 Worker 时使用 GlobalTracer 即可
func InitTracer(cfg tracingCfg.TracingSt) (err error) { jCfg := jConfig.Configuration{ ServiceName: cfg.Sid, Sampler: &jConfig.SamplerConfig{ Type: jaeger.SamplerTypeConst, Param: 1.0, SamplingServerURL: cfg.SamplingServerURL, }, Reporter: &jConfig.ReporterConfig{ BufferFlushInterval: time.Second, LocalAgentHostPort: cfg.LocalAgentHostPort, CollectorEndpoint: CollectorEndpoint, }, } tracer, closer, err := jCfg.NewTracer(jConfig.Logger(jaeger.StdLogger)) if err != nil { return err } opentracing.SetGlobalTracer(tracer) _ = closer return } -
对于某些特殊的场景,如”下载文件-处理文件-删除文件“,Temporal 提供 ”会话“ 机制,可以将相关的步骤绑定在统一个 Worker 上执行,可以方便开发者拆分更小的工作流活动。要使用此功能,要记得打开worker的配置(代码见上述创建 Worker 处)
Temporal 任务的分发都是通过任务队列完成的,Session 的主要原理是设置一个只能由某 Worker 读取的队列,将对应的活动只放入该队列中。因此在后续配置活动、子工作流的 options 时不能覆盖 ctx,否则会丢失 Session 元数据而失效,具体请参阅文档
当前 Temporal 还无法将 Session 信息传递到子工作流,如果想要在子工作流中使用 Session 绑定,可以使用
workflow.GetSessionInfo(sessionCtx).GetRecreateToken()获取 Session Token 传递到子工作流中,在子工作流中使用workflow.RecreateSession重建 Session另一种方法是抛弃子工作流,在整体工作流中使用 workflow.Go 进行并发活动执行,使用同一个 sessionCtx,要注意对结果的获取处理和协程的等待。这种方法也能更好的展示工作流执行历史,也方便进行 Tracing
文档与实例
如果你已经搭建好了 Temporal,不妨阅读一下官方提供的文档,做一个 Hello World 程序来检验你的成果,并在文档与样例中发现更多 Temporal 支持的特性。
官方文档中主要包括 Temporal 的特性介绍、常见的使用场景、如何使用 Temporal 以及 Go、Java 客户端。
为例方便自己也方便其他不想读英文的同学,我对官方文档的特性介绍和 Go 客户端部分做了翻译:翻译后文档地址
除此之外,Temporal 官方提供了运行样例:Golang SDK 样例,该样例能很好的阐释一些 Temporal 的特性并告诉你想使用它时代码该如何编写,为了方便起见我简单做了一个样例介绍,方便有需要的同学想要了解相关特性时快速查找样例,介绍附在了翻译文档的最后一篇
完结
目前无论是 Temporal 还是 Cadence,代码分支和社区都非常活跃,Temporal 的 Github star history 也在快速上升。但在国内还很少看到有介绍这个组件的相关资料,也算是草草总结了一下自己在使用 Temporal 时踩的坑,希望能对有需要的同学提供一些帮助,也欢迎大家随时与我交流,毕竟实战时可能踩的坑远不止这些。
除此之外也希望两个社区都能蓬勃发展并多向国内辐射一些内容,大家也都能参与到其中并贡献自己的一份力量。